|
AIfES 2
2.0.0
|
|
AIfES 2
2.0.0
|
This tutorial should explain how the different components of AIfES 2 work together to perform an inference (/ prediction / forward pass) on a simple Feed-Forward Neural Network (FNN) or Multi Layer Perceptron (MLP). It is assumed, that the trained weights are already available or will be calculated with external tools on a PC. If you want to train the neural network with AIfES, switch to the training tutorial.
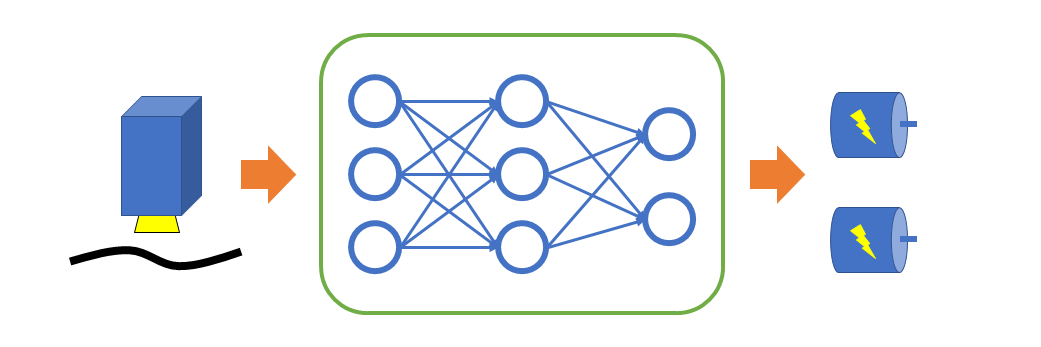
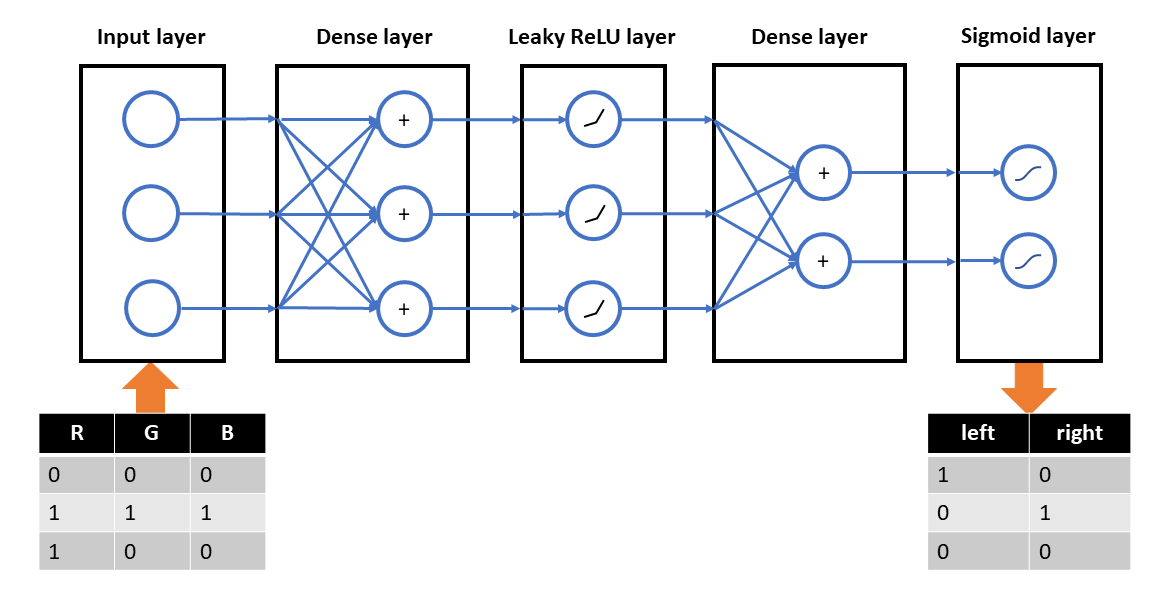
As an example, we take a robot with two powered wheels and a RGB color sensor that should follow a black line on a white paper. To fulfill the task, we map the color sensor values with an FNN directly to the control commands for the two wheel-motors of the robot. The inputs for the FNN are the RGB color values scaled to the interval [0, 1] and the outputs are either "on" (1) or "off" (0) to control the motors.

The following cases should be considered:
The resulting input data of the FNN is then
| R | G | B |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 1 | 0 | 0 |
and the output should be
| left motor | right motor |
|---|---|
| 1 | 0 |
| 0 | 1 |
| 0 | 0 |
To set up the FNN in AIfES 2, we need to design the structure of the neural network. It needs three inputs for the RGB color values and two outputs for the two motors. Because the task is rather easy, we use just one hidden layer with three neurons.
To create the network in AIfES, it must be divided into logical layers like the fully-connected (dense) layer and the activation functions. We choose a Leaky ReLU activation for the hidden layer and a Sigmoid activation for the output layer.
To perform an inference you need the trained weights and biases of the model. For example you can train your model with Keras or PyTorch, extract the weights and biases and copy them to your AIfES model.
For a dense layer, AIfES expects the weights as a matrix of shape [Inputs x Outputs] and the bias as a matrix of shape [1 x Outputs].
Example model in Keras:
Example model in PyTorch:
Our example weights and biases for the two dense layers after training are:
\[ w_1 = \left( \begin{array}{c} 3.64540 & -3.60981 & 1.57631 \\ -2.98952 & -1.91465 & 3.06150 \\ -2.76578 & -1.24335 & 0.71257 \end{array}\right) \]
\[ b_1 = \left( \begin{array}{c} 0.72655 & 2.67281 & -0.21291 \end{array}\right) \]
\[ w_2 = \left( \begin{array}{c} -1.09249 & -2.44526 \\ 3.23528 & -2.88023 \\ -2.51201 & 2.52683 \end{array}\right) \]
\[ b_2 = \left( \begin{array}{c} 0.14391 & -1.34459 \end{array}\right) \]
AIfES provides implementations of the layers for different data types that can be optimized for several hardware platforms. An overview of the layers that are available for inference can be seen in the overview section of the main page. In the overview table you can click on the layer in the first column for a description on how the layer works. To see how to create the layer in code, choose one of the implementations for your used data type and click on the link.
In this tutorial we work with the float 32 data type (F32 ) and use the default implementations (without any hardware specific optimizations) of the layers.
Used layer types:
Used implementations:
For every layer we need to create a variable of the specific layer type and configure it for our needs. See the documentation of the data type and hardware specific implementations (for example ailayer_dense_f32_default()) for code examples on how to configure the layers.
Our designed network can be declared with the following code.
We use the initializer macros with the "_M" at the end, because we need to set our parameters (like the weights) to the layers.
Afterwards the layers are connected and initialized with the data type and hardware specific implementations
To see the structure of your created model, you can print a model summary to the console
Because AIfES doesn't allocate any memory on its own, you have to set the memory buffers for the inference manually. This memory is required for example for the intermediate results of the layers. Therefore you can choose fully flexible, where the buffer should be located in memory. To calculate the required amount of memory for the inference, the aialgo_sizeof_inference_memory() function can be used.
With aialgo_schedule_inference_memory() a memory block of the required size can be distributed and scheduled (memory regions might be shared over time) to the model.
A dynamic allocation of the memory using malloc could look like the following:
You could also pre-define a memory buffer if you know the size in advance, for example
To perform the inference, the input data must be packed in a tensor to be processed by AIfES. A tensor in AIfES is just a N-dimensional array that is used to hold the data values in a structured way. To do this in the example, create a 2D tensor of the used data type. The shape describes the size of the dimensions of the tensor. The first dimension (the rows) is the batch dimension, i.e. the dimension of the different input samples. If you process just one sample at a time, this dimension is 1. The second dimension equals the inputs of the neural network.
Now everything is ready to perform the actual inference. For this you can use the function aialgo_inference_model().
Alternative you can also do the inference without creating an empty tensor for the result with the function aialgo_forward_model(). The results of this function are stored in the inference memory. If you want to perform another inference or delete the inference memory, you have to save the results first to another tensor / array. Otherwise you will loose the data.
Afterwards you can print the results to the console for debugging purposes: